However, the dual-write problem isn’t unique to event-driven systems or Kafka. It occurs in many situations involving different technologies and architectures.
When I started building event-driven systems, I encountered the dual-write problem almost immediately. I eventually learned effective ways to solve it but tripped over some anti-patterns along the way.
I want to break down the details of the dual-write problem so you can understand how it occurs and avoid making the same mistakes I did. I’ll outline a few anti-patterns that might look promising, but don’t solve the problem. Finally, we’ll look at accepted solutions that eliminate the dual-write problem.
Read on for a few techniques that will not work (assuming you are using Apache Kafka to flow events into some external systems) and some that will.
In this video, I provide a primer on logistic regression, including a demystification of the name. Is it regression? Is it classification? Find out!
I have a lot of fun with this “Is logistic regression actually a regression technique, or is it secretly a classification technique?” I think this video is the single clearest explanation I’ve given on that question, which probably says something about my prior explanations.
XML is a common storage format for data, metadata, parameters, or other semi-structured data. Because of this, it often finds its way into SQL Server databases and needs to be managed alongside other data types.
Even though a relational database is not the optimal place to store and manage XML data, it is often needed due to application requirements, convenience, or a need to maintain this information in close proximity to other app data.
This article dives into a variety of common XML challenges and the functionality included in SQL Server to help make managing them as simple as possible.
Ed does a good job of walking through what you can do. My general philosophy on XML and JSON in the database is simple: if you simply want a place to store some JSON or XML outputs and retrieve the results exactly as they are without performing any searches or transformations, write as JSON/XML. If you want to use the database to search through JSON/XML records for particular attributes and values, or if you want to reshape the JSON/XML data within the database, create a proper data model for this input.
In this case, we want to store departments and employees. Every department will need a leader, and every employee will need a department. We cannot have a department without a department leader – but we cannot have an employee without a department either.
Click through to see how you can resolve this kind of paradox with Postgres.
This blog post will walk you through how to access Oracle OCI Object Storage and explore what buckets and files you have there, using Python and the OCI Python library. There will be additional posts which will walk through some of the other typical tasks you’ll need to perform with moving files into and out of OCI Object Storage.
It looks like the interface for this is substantially similar to AWS’s S3.
To be honest, I can’t remember that one Power BI feature caused so much hype as the Fields parameter, even though it was introduced exactly 2 years ago (May 2022)! I firmly believe that the Fields parameter is one of the things that will forever change the way we are building user experience in Power BI.
One important disclaimer before we jump into the action: Field params is still a preview feature. That means, don’t be surprised if you open Power BI Desktop and you don’t see an option to use Field params. You first need to enable this feature under Options & Settings -> Options -> Preview features.
Read on to see how you can use field parameters to make reports more dynamic.
It is not easy to understand what’s going on when you run into an I/O related performance problem on an Azure Virtual Machine. It is a common, but complex problem. What you need is to figure out what’s happening at both the host level and your SQL Server instance where often, correlating host metrics with SQL Server workloads can be a challenge.
We developed a new experience that helps you do exactly that.
Click through to see how it works. Given that awful disk latency is a common problem in the cloud, this may at least tell you if you have things set up correctly.
How often do you evaluate your Query Store configuration? Have you ever had Query Store configured in READ_WRITE mode only to return later and find it in READ_ONLY mode instead? It may be simple enough to switch back to READ_WRITE and carry on with your day, but you would be wise to track down what happened to cause the switch to READ_ONLY.
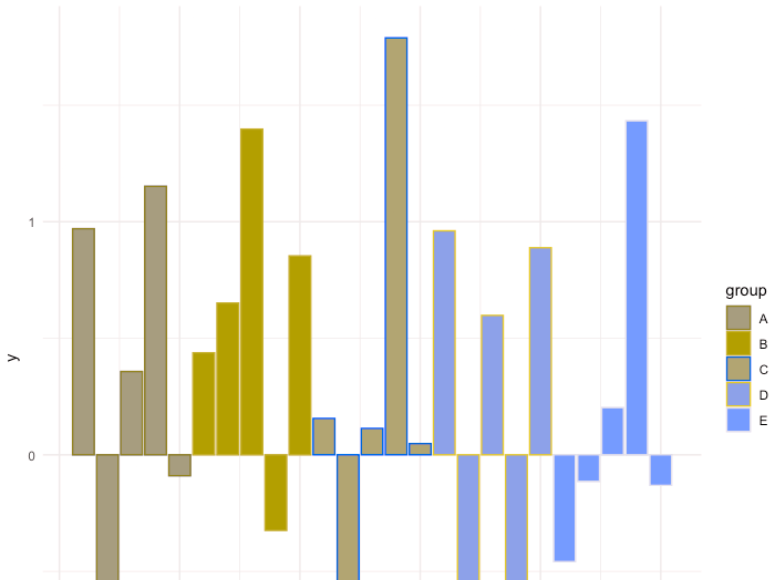
A simple, yet effective way to set your colour palette in R using ggplot library.
Click through for the demonstration. Tomaz keeps the text very light in this post, so I’ll do a little vamping of my own. Creating a custom palette is neat, but do make sure that your custom palette works for users with color vision deficiency (CVD). Taking Tomaz’s bar chart into Coblis (an amazing tool I continue to use quite regularly), here’s what it looks like for people with protanopia—that is, no red cones in their eyes:
It’s not awful, particularly because Tomaz changed the fill but not the border color, so you get a funky striation effect.
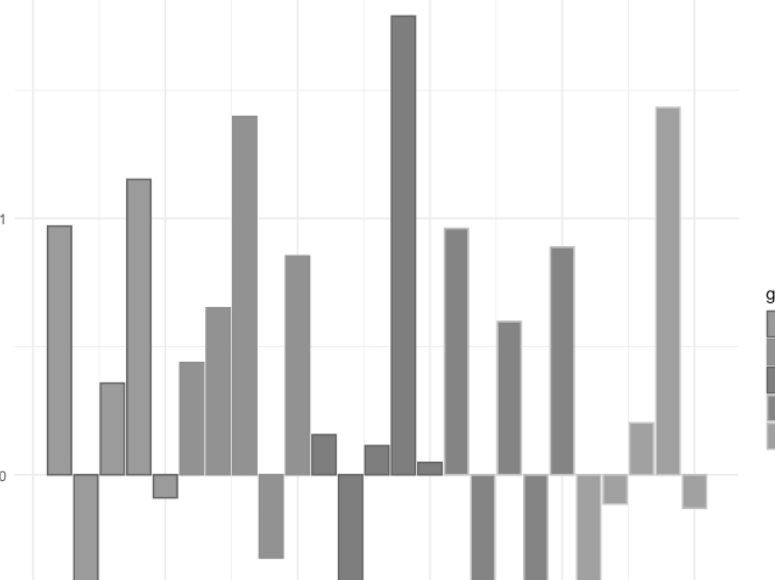
But the real kicker is if you switch to the monochromatic option in Coblis.
Granted, I know of exactly one person with monochromacy, so if you want to be fair, this isn’t one I’d check for on a webpage. But the large majority of technical books have grayscale images because it saves money on printing, so if this were your sweet-looking color scheme and you’re adding the image into a book, readers would need to focus particularly hard on the bars to figure anything out.