Arthur Daniels explains that missing indexes can cause high wait stat counts to appear:
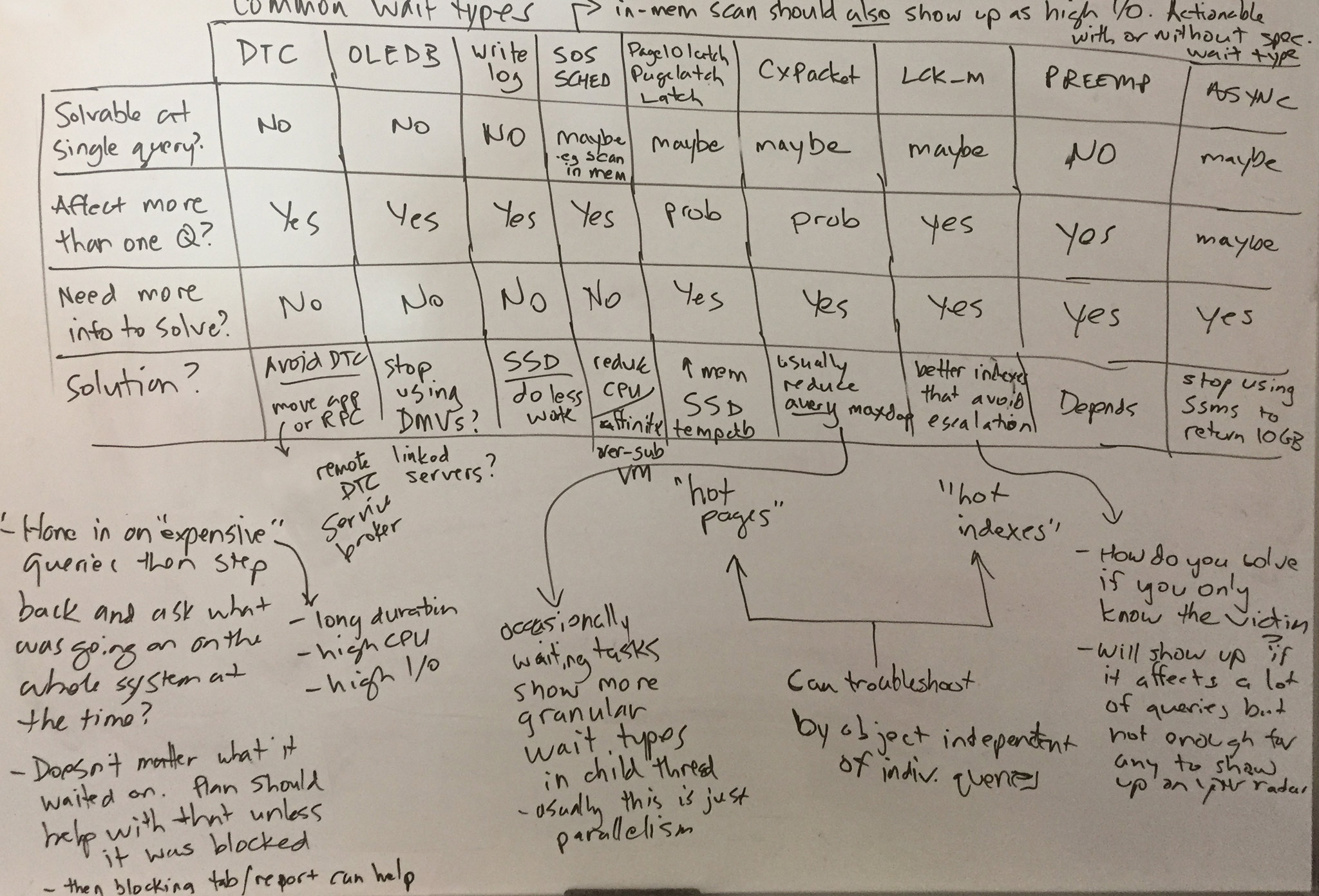
At first, this statement might sound a bit confusing. Usually, we expect wait statistics to show us what a query is waiting on, whether it’s waiting on memory, loading pages from disk, or any of the other numerous wait types.
Once you start collecting wait statistics, you’ll have a lot of data to sort through. You might find waits like CX_PACKET, CX_CONSUMER, and PAGEIOLATCH. Surprisingly, these could mean that your databases aren’t well indexed.
This makes sense. At its core, wait stats tell you where SQL Server is hurting: where is the bottleneck. But just like a person at the doctor, SQL Server can only be so specific in how it relates this pain to you, and that specificity generally boils down to hardware components. The solution might be “get more hardware,” but as Arthur points out, writing better queries and using better indexes can mitigate those pains too.
{kind=link}
{kind=link}