Allen White walks us through a problem he experienced recently:
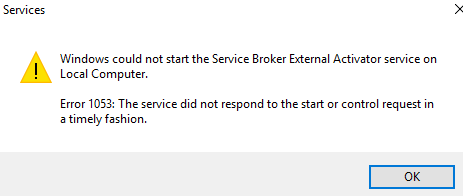
My test environment is running SQL Server 2017 on Windows Server 2016, a pretty vanilla environment. After downloading the appropriate installer for the server where the service was to run, I installed it, made the necessary changes to the config file per the documentation provided after installation, assigned the service account with the necessary privileges, and attempted to start the service.
In the Windows System error log, I got three messages.
{kind=link}
Read on for the solution.
Comments closed