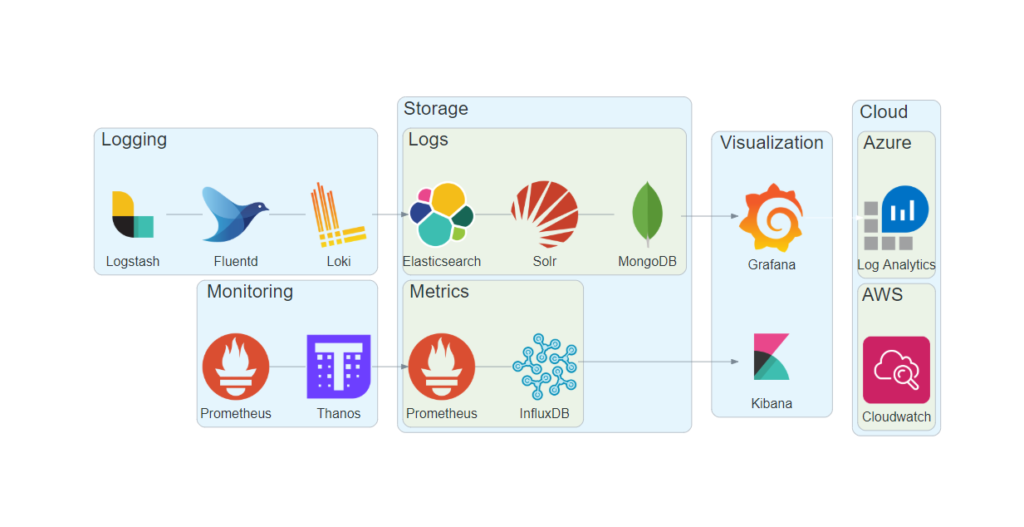
Marc Lelijveld has some icons for us:
Previously, I used a simple PowerPoint slide when I drafted technical solution proposals. This took me a whole lot of time by copy-pasting all the images, make it look nice and connect the dots together. While tools like diagrams.net are built for this purpose, I always stuck with PowerPoint as there were no icons for all Power BI objects in this tool. Until now!
The online tool Diagrams.net allow you to quickly draft your solution architecture by dragging and dropping icons on a white canvas and easily connecting the dots together.
I’ve been a big fan of diagrams.net (nee draw.io), so thank you Marc for putting this together.
Comments closed