This blog post will walk you through how to access Oracle OCI Object Storage and explore what buckets and files you have there, using Python and the OCI Python library. There will be additional posts which will walk through some of the other typical tasks you’ll need to perform with moving files into and out of OCI Object Storage.
It looks like the interface for this is substantially similar to AWS’s S3.
To be honest, I can’t remember that one Power BI feature caused so much hype as the Fields parameter, even though it was introduced exactly 2 years ago (May 2022)! I firmly believe that the Fields parameter is one of the things that will forever change the way we are building user experience in Power BI.
One important disclaimer before we jump into the action: Field params is still a preview feature. That means, don’t be surprised if you open Power BI Desktop and you don’t see an option to use Field params. You first need to enable this feature under Options & Settings -> Options -> Preview features.
Read on to see how you can use field parameters to make reports more dynamic.
How often do you evaluate your Query Store configuration? Have you ever had Query Store configured in READ_WRITE mode only to return later and find it in READ_ONLY mode instead? It may be simple enough to switch back to READ_WRITE and carry on with your day, but you would be wise to track down what happened to cause the switch to READ_ONLY.
It is not easy to understand what’s going on when you run into an I/O related performance problem on an Azure Virtual Machine. It is a common, but complex problem. What you need is to figure out what’s happening at both the host level and your SQL Server instance where often, correlating host metrics with SQL Server workloads can be a challenge.
We developed a new experience that helps you do exactly that.
Click through to see how it works. Given that awful disk latency is a common problem in the cloud, this may at least tell you if you have things set up correctly.
In the world of search engines and data retrieval, achieving high accuracy and relevance in the results is a constant challenge. One of the techniques used to improve search results is Fuzzy Search.
This blog post will delve into the concept of fuzzy search, its implementation using the Levenshtein Distance, and how to test its effectiveness.
Levenshtein distance is also one of the techniques spell checkers use, comparing word not in its dictionary to other words within a certain distance.
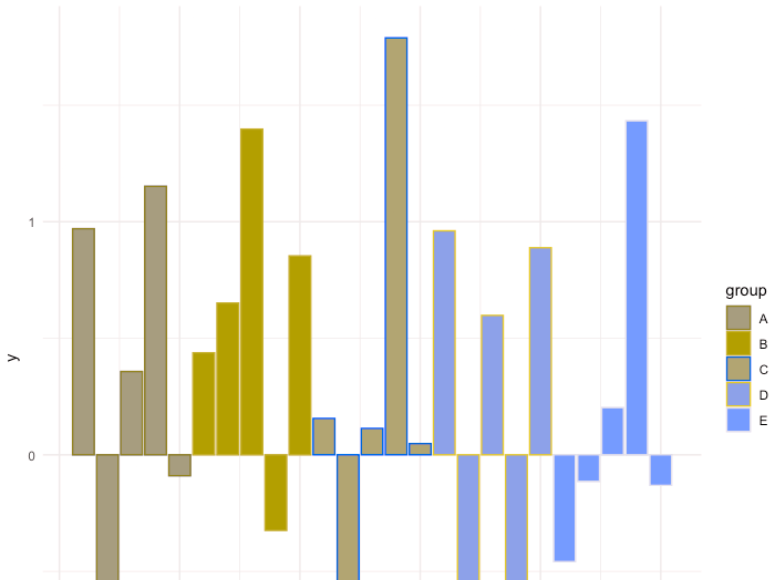
A simple, yet effective way to set your colour palette in R using ggplot library.
Click through for the demonstration. Tomaz keeps the text very light in this post, so I’ll do a little vamping of my own. Creating a custom palette is neat, but do make sure that your custom palette works for users with color vision deficiency (CVD). Taking Tomaz’s bar chart into Coblis (an amazing tool I continue to use quite regularly), here’s what it looks like for people with protanopia—that is, no red cones in their eyes:
It’s not awful, particularly because Tomaz changed the fill but not the border color, so you get a funky striation effect.
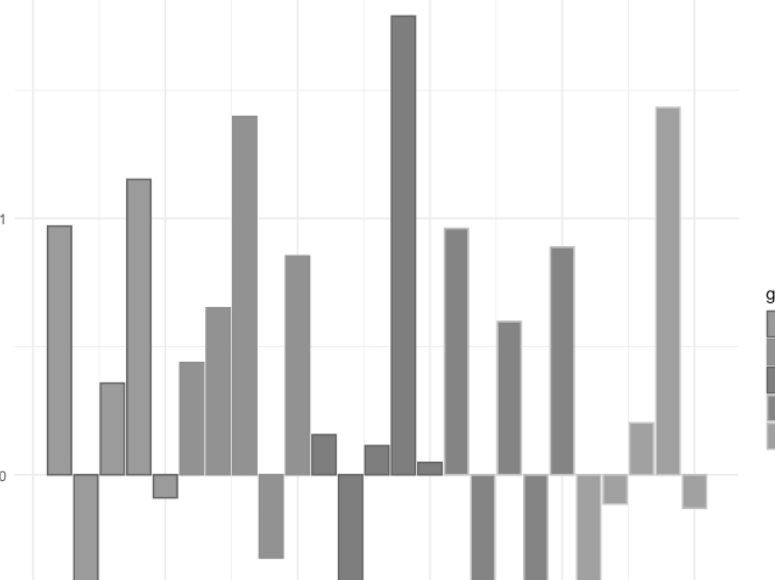
But the real kicker is if you switch to the monochromatic option in Coblis.
Granted, I know of exactly one person with monochromacy, so if you want to be fair, this isn’t one I’d check for on a webpage. But the large majority of technical books have grayscale images because it saves money on printing, so if this were your sweet-looking color scheme and you’re adding the image into a book, readers would need to focus particularly hard on the bars to figure anything out.
The CONTROL SERVER permission has been around since SQL Server 2005, and is the most powerful permission granted as part of membership in the sysadmin role. What many folks don’t realize is that this permission can be granted to a login or group without including them in the sysadmin role. And that can become problematic if, as an administrator, you aren’t aware of logins or groups that don’t have this permission.
Jeff points out how CONTROL SERVER isn’t quite the same as sysadmin, but why you should still treat it that way.
Effective reports and dashboards should enable users to quickly answer their data questions so that they can focus on their primary business tasks and responsibilities. To help you design effective reports, we introduce the3-30-300 rule for information design.The 3-30-300 rule is a straightforward and practical approach for you to produce efficient report layouts by structuring reports in a functionally hierarchical way. This rule concisely paraphrases the visual information-seeking mantra from Ben Schneidermann (1996). To make it easier to understand for Power BI developers, we express this rule with respect to approximately how long it should take users to get certain information or perform certain tasks in a report.
It’s a clever mnemonic and Kurt does a good job of showing how you could implement it.
Let’s have devs look at their own query performance. Yes, please, sign me up for that! Sometimes, it’s hard for me to know the best course of action, especially when they are using Entity Framework, but it’s a great start for them to use Query Store to see how impactful their queries are. I’m happy to help them decipher results if they are confused, but I really like performance tuning being a team sport. I was giving them a list of queries with, for example, high CPU usage, but it was even better when they could go in there and use Query Store for themselves on a regular basis.
The actual granting of rights takes a couple lines of T-SQL, and Josephine also provides an overview of Query Store along the way. Erik Darling’s sp_QuickieStore plays a prominent role in this post and I agree that it’s extremely helpful. I’d also be remiss not bringing up QDS Toolbox as well, as it’s a rather good solution in its own right.
We’re already at part 31 of the plansplaining series. And this is also the third part in my discussion of execution plans for cursors. After explaining the basics, and after diving into static cursors, it is now time to investigate dynamic cursors. As a quick reminder, recall that a static cursor presents data as it was when the cursor was opened (and does so by simply saving a snapshot of that data in tempdb), whereas a dynamic cursor is supposed to see all changes that are committed while the cursor is open. Let’s see how this change in semantics affects the execution plan.
Read on as Hugo gives it the college try and also admits he might be missing something in the explanation.